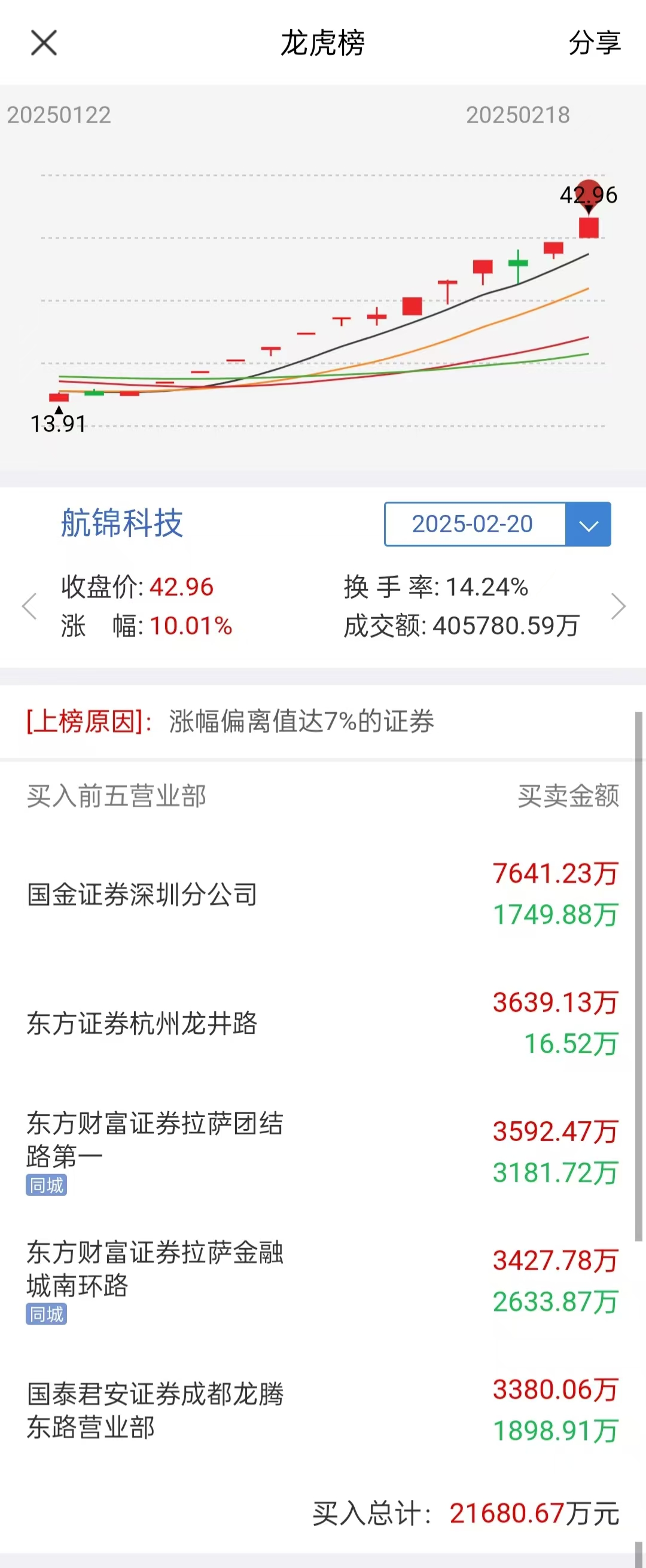
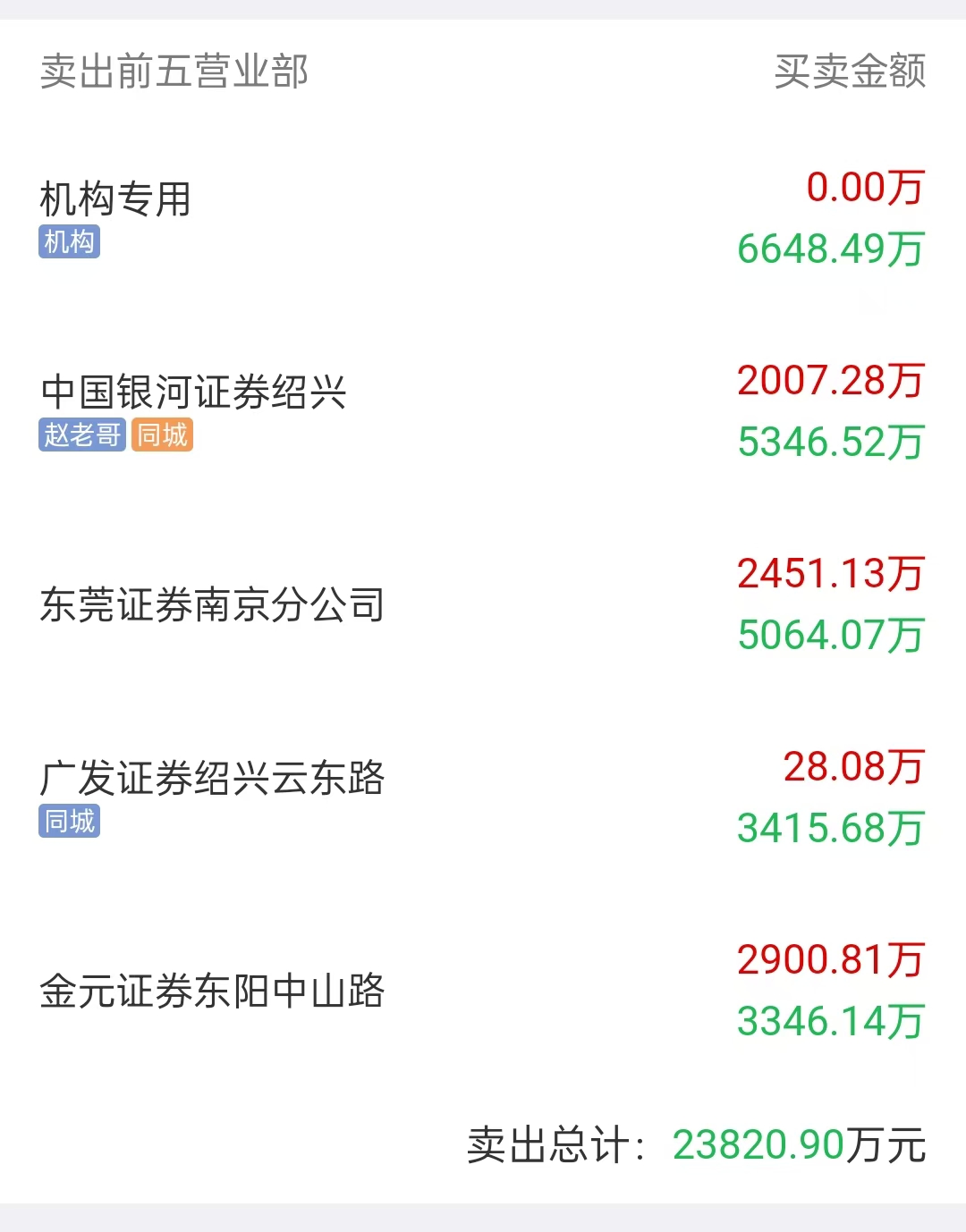
18:48
291阅读 20:09
939阅读 17:42
239阅读 20:01
19阅读 20:25
温氏股份发布业绩快报,2024年实现营业总收入1049.06亿元,同比增长16.66%;净利润92.45亿元,上年同期亏损63.9亿元;基本每股收益1.39元。报告期内,公司核心生产指标持续改善,生产持续向好,同时叠加饲料原料价格下降的影响,公司养殖成本同比大幅下降。此外,公司肉猪销量同比增长,销售价格同比上升,公司生猪养殖业务利润同比大幅上升,实现扭亏为盈。
333阅读 19:44
沪ICP备17025576号